 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUEL: Adversarial Self-Play for Multimodal Reasoning
May 24, 2026Reinforcement learning (RL) has emerged as an effective paradigm for improving the reasoning capability of vision-language models (VLMs). However, RL-based optimization typically depends on costly high-quality annotations that are difficult to scale. Existing unsupervised alternatives may drift toward biased solutions due to weak visual grounding and the lack of reliable verification signals. We propose a self-evolving post-training framework, DUEL, where supervision emerges from adversarial interactions between two policies initialized from the same pretrained VLM. A Challenger generates an image-grounded true claim together with a minimally perturbed hard-negative counterpart, while a Solver verifies both claims against the image, encouraging fine-grained visual discrimination under near-neighbor semantics. To stabilize optimization, we introduce a length-normalized log-likelihood reward that preserves informative optimization signals beyond binary outcome supervision and improves learning stability under sparse feedback. Experiments show that DUEL consistently improves visual reasoning and robust discrimination without additional human annotations, external reward models, or image editing tools.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
AMemGym: Interactive Memory Benchmarking for Assistants in Long-Horizon Conversations
Mar 02, 2026Long-horizon interactions between users and LLM-based assistants necessitate effective memory management, yet current approaches face challenges in training and evaluation of memory. Existing memory benchmarks rely on static, off-policy data as context, limiting evaluation reliability and scalability. To address these gaps, we introduce AMemGym, an interactive environment enabling on-policy evaluation and optimization for memory-driven personalization. AMemGym employs structured data sampling to predefine user profiles, state-dependent questions, and state evolution trajectories, enabling cost-effective generation of high-quality, evaluation-aligned interactions. LLM-simulated users expose latent states through role-play while maintaining structured state consistency. Comprehensive metrics based on structured data guide both assessment and optimization of assistants. Extensive experiments reveal performance gaps in existing memory systems (e.g., RAG, long-context LLMs, and agentic memory) and corresponding reasons. AMemGym not only enables effective selection among competing approaches but also can potentially drive the self-evolution of memory management strategies. By bridging structured state evolution with free-form interactions, our framework provides a scalable, diagnostically rich environment for advancing memory capabilities in conversational agents.
Beyond Instrumental and Substitutive Paradigms: Introducing Machine Culture as an Emergent Phenomenon in Large Language Models
Jan 23, 2026Recent scholarship typically characterizes Large Language Models (LLMs) through either an \textit{Instrumental Paradigm} (viewing models as reflections of their developers' culture) or a \textit{Substitutive Paradigm} (viewing models as bilingual proxies that switch cultural frames based on language). This study challenges these anthropomorphic frameworks by proposing \textbf{Machine Culture} as an emergent, distinct phenomenon. We employed a 2 (Model Origin: US vs. China) $\times$ 2 (Prompt Language: English vs. Chinese) factorial design across eight multimodal tasks, uniquely incorporating image generation and interpretation to extend analysis beyond textual boundaries. Results revealed inconsistencies with both dominant paradigms: Model origin did not predict cultural alignment, with US models frequently exhibiting ``holistic'' traits typically associated with East Asian data. Similarly, prompt language did not trigger stable cultural frame-switching; instead, we observed \textbf{Cultural Reversal}, where English prompts paradoxically elicited higher contextual attention than Chinese prompts. Crucially, we identified a novel phenomenon termed \textbf{Service Persona Camouflage}: Reinforcement Learning from Human Feedback (RLHF) collapsed cultural variance in affective tasks into a hyper-positive, zero-variance ``helpful assistant'' persona. We conclude that LLMs do not simulate human culture but exhibit an emergent Machine Culture -- a probabilistic phenomenon shaped by \textit{superposition} in high-dimensional space and \textit{mode collapse} from safety alignment.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
CATArena: Evaluation of LLM Agents through Iterative Tournament Competitions
Oct 30, 2025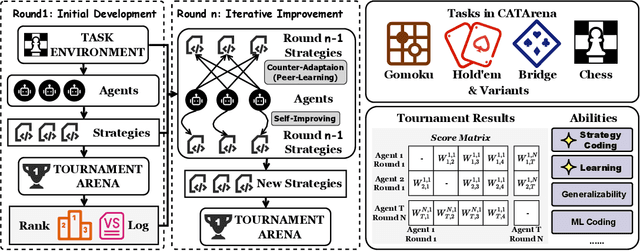
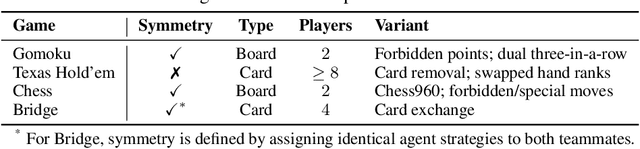
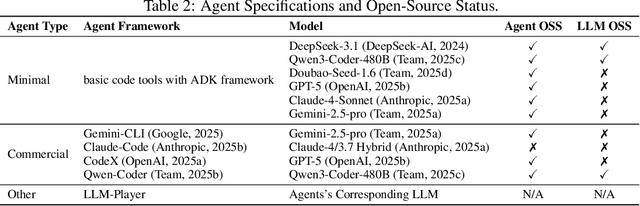
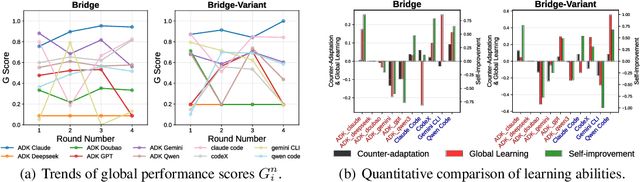
Large Language Model (LLM) agents have evolved from basic text generation to autonomously completing complex tasks through interaction with external tools. However, current benchmarks mainly assess end-to-end performance in fixed scenarios, restricting evaluation to specific skills and suffering from score saturation and growing dependence on expert annotation as agent capabilities improve. In this work, we emphasize the importance of learning ability, including both self-improvement and peer-learning, as a core driver for agent evolution toward human-level intelligence. We propose an iterative, competitive peer-learning framework, which allows agents to refine and optimize their strategies through repeated interactions and feedback, thereby systematically evaluating their learning capabilities. To address the score saturation issue in current benchmarks, we introduce CATArena, a tournament-style evaluation platform featuring four diverse board and card games with open-ended scoring. By providing tasks without explicit upper score limits, CATArena enables continuous and dynamic evaluation of rapidly advancing agent capabilities. Experimental results and analyses involving both minimal and commercial code agents demonstrate that CATArena provides reliable, stable, and scalable benchmarking for core agent abilities, particularly learning ability and strategy coding.
Instance-level Randomization: Toward More Stable LLM Evaluations
Sep 16, 2025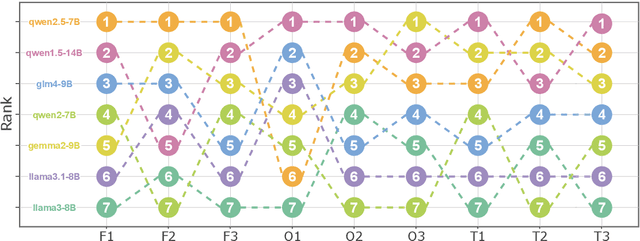

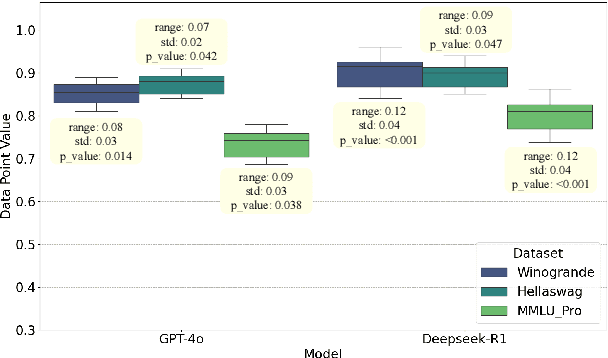
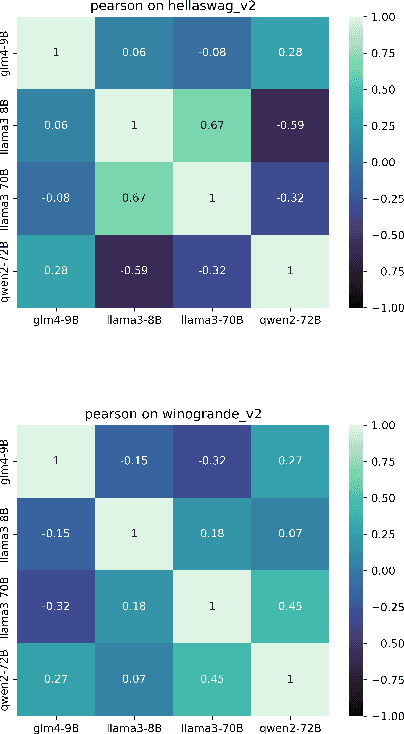
Evaluations of large language models (LLMs) suffer from instability, where small changes of random factors such as few-shot examples can lead to drastic fluctuations of scores and even model rankings. Moreover, different LLMs can have different preferences for a certain setting of random factors. As a result, using a fixed setting of random factors, which is often adopted as the paradigm of current evaluations, can lead to potential unfair comparisons between LLMs. To mitigate the volatility of evaluations, we first theoretically analyze the sources of variance induced by changes in random factors. Targeting these specific sources, we then propose the instance-level randomization (ILR) method to reduce variance and enhance fairness in model comparisons. Instead of using a fixed setting across the whole benchmark in a single experiment, we randomize all factors that affect evaluation scores for every single instance, run multiple experiments and report the averaged score. Theoretical analyses and empirical results demonstrate that ILR can reduce the variance and unfair comparisons caused by random factors, as well as achieve similar robustness level with less than half computational cost compared with previous methods.
OIBench: Benchmarking Strong Reasoning Models with Olympiad in Informatics
Jun 12, 2025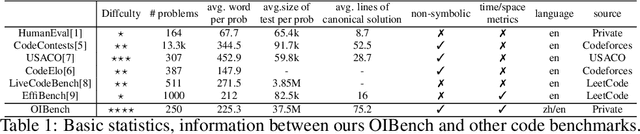

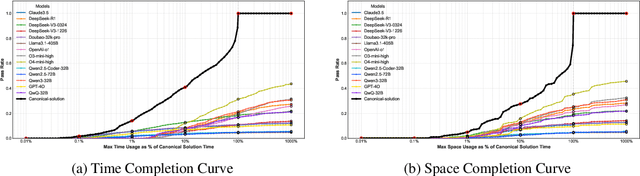
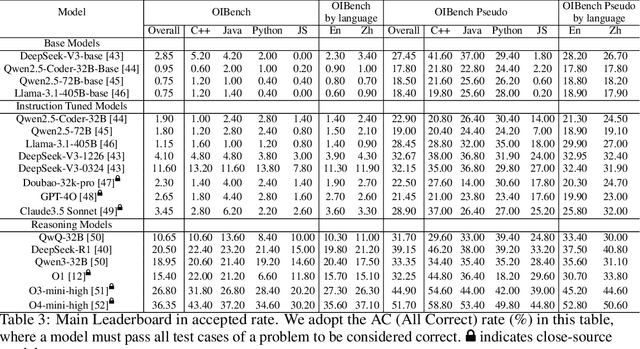
As models become increasingly sophisticated, conventional algorithm benchmarks are increasingly saturated, underscoring the need for more challenging benchmarks to guide future improvements in algorithmic reasoning. This paper introduces OIBench, a high-quality, private, and challenging olympiad-level informatics dataset comprising 250 carefully curated original problems. We detail the construction methodology of the benchmark, ensuring a comprehensive assessment across various programming paradigms and complexities, and we demonstrate its contamination-resistant properties via experiments. We propose Time/Space Completion Curves for finer-grained efficiency analysis and enable direct human-model comparisons through high-level participant evaluations. Our experiments reveal that while open-source models lag behind closed-source counterparts, current SOTA models already outperform most human participants in both correctness and efficiency, while still being suboptimal compared to the canonical solutions. By releasing OIBench as a fully open-source resource (https://huggingface.co/datasets/AGI-Eval/OIBench), we hope this benchmark will contribute to advancing code reasoning capabilities for future LLMs.
Audio Turing Test: Benchmarking the Human-likeness of Large Language Model-based Text-to-Speech Systems in Chinese
May 16, 2025Recent advances in large language models (LLMs) have significantly improved text-to-speech (TTS) systems, enhancing control over speech style, naturalness, and emotional expression, which brings TTS Systems closer to human-level performance. Although the Mean Opinion Score (MOS) remains the standard for TTS System evaluation, it suffers from subjectivity, environmental inconsistencies, and limited interpretability. Existing evaluation datasets also lack a multi-dimensional design, often neglecting factors such as speaking styles, context diversity, and trap utterances, which is particularly evident in Chinese TTS evaluation. To address these challenges, we introduce the Audio Turing Test (ATT), a multi-dimensional Chinese corpus dataset ATT-Corpus paired with a simple, Turing-Test-inspired evaluation protocol. Instead of relying on complex MOS scales or direct model comparisons, ATT asks evaluators to judge whether a voice sounds human. This simplification reduces rating bias and improves evaluation robustness. To further support rapid model development, we also finetune Qwen2-Audio-Instruct with human judgment data as Auto-ATT for automatic evaluation. Experimental results show that ATT effectively differentiates models across specific capability dimensions using its multi-dimensional design. Auto-ATT also demonstrates strong alignment with human evaluations, confirming its value as a fast and reliable assessment tool. The white-box ATT-Corpus and Auto-ATT can be found in ATT Hugging Face Collection (https://huggingface.co/collections/meituan/audio-turing-test-682446320368164faeaf38a4).
Deepfake-Eval-2024: A Multi-Modal In-the-Wild Benchmark of Deepfakes Circulated in 2024
Mar 05, 2025


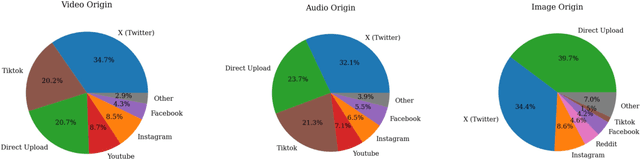
In the age of increasingly realistic generative AI, robust deepfake detection is essential for mitigating fraud and disinformation. While many deepfake detectors report high accuracy on academic datasets, we show that these academic benchmarks are out of date and not representative of real-world deepfakes. We introduce Deepfake-Eval-2024, a new deepfake detection benchmark consisting of in-the-wild deepfakes collected from social media and deepfake detection platform users in 2024. Deepfake-Eval-2024 consists of 45 hours of videos, 56.5 hours of audio, and 1,975 images, encompassing the latest manipulation technologies. The benchmark contains diverse media content from 88 different websites in 52 different languages. We find that the performance of open-source state-of-the-art deepfake detection models drops precipitously when evaluated on Deepfake-Eval-2024, with AUC decreasing by 50\% for video, 48\% for audio, and 45\% for image models compared to previous benchmarks. We also evaluate commercial deepfake detection models and models finetuned on Deepfake-Eval-2024, and find that they have superior performance to off-the-shelf open-source models, but do not yet reach the accuracy of deepfake forensic analysts. The dataset is available at https://github.com/nuriachandra/Deepfake-Eval-2024.